I presented a paper in "2011 International Conference on Software and Computer Applications". Following is my speech along with corresponding slides.
Good Afternoon! I’m Dileepa from university of Moratuwa, Sri Lanka and I’m going to talk about a framework I developed for automated log file analysis.
First, I’ll explain the background and then the problem identification. After that, I’ll talk about the overview of the solution which is the new framework, and then the design and implementation of it. This section will include an experiment I did as a proof of concept. Finally I will conclude the work.

Software log files are analyzed for many reasons by different professionals. Testers use them to check the conformance of a software to a given functionality. For example, in a system where messages are passed between different processes, a QA engineer can perform a certain action and then check the log to see whether the correct messages are generated. The developers analyze logs mainly for troubleshooting. When something goes wrong in production sites or even when a bug is reported by an outsourced QA firm, the most useful resource available for the developer to troubleshoot is the application log file most of the time. Domain experts also use logs sometimes for troubleshooting and the system admins monitor logs to confirm that everything is working fine in the overall system level.

Now we see that it’s always a human user who analyzes a log file in a given scenario. However, with the increasing complexity of software systems and the demands for high speed high volume operations this complete manual process has become a near impossibility. First, one needs an expert for log file analysis which inflicts a cost and even with expertise it’s a labor intensive task. More often than not log file analysis is a repetitive and a boring task resulting in human errors. It’s highly likely that when analyzing a certain log for a period of time one can identify recurring patterns. Ideally those patterns should be automated. In most cases it is essential to automate at least a part of the analysis process.

However, automation is not free of challenges. One big problem is that log files have different structures and format. To make things worse, the structure and format change over time. There’s no platform to automate log analysis in a generic way. When automating analysis, one needs to create some rules and put them in a machine readable way. Then, to manage those rules or to reuse them, they need to be kept in a human readable way too. Keeping things both machine and human readable is not an easy task. Because of these challenges, most organizations completely abandon automation and others go for proprietary implementations in general purpose languages. That inflicts a significant cost because every log analysis procedure needs to be implemented from scratch without reuse. When implemented in a general purpose language the rules are not readable particularly for non-developers. If not designed properly to deal with changes with an additional cost, it will be difficult to add new rules later and handle log file format and structure changes. Another significant problem is that proprietary automations come up with fixed reports which cannot be customized.

So there are many facts that stand for the need for a common platform for generic log file analysis. Some level of support already exists. For example, we have xml which is a universal format used everywhere. It’s a good candidate for keeping log information. Many tools are freely available to process xml. However, xml comes with a cost; the spatial cost for meta data. This makes it inappropriate for certain kinds of logs. In addition it is not very human readable. There are many languages available for processing, but they look almost like other general purpose languages. They are not for non-developer. Not every log file is in xml. There are lot of other text formats plus binary formats.
Researchers have done some work on creating formal definitions for log files. They are based on regular expressions and assume a log file consisting of line entries. Therefore these existing definitions do not help with log files with complex structures which is very common. Also they are unable to handle difficult syntax that cannot be resolved with a regular grammar even in line logs. Another flaw is that these definitions do not take any advantage from xml.
What are the expected features from a framework for generic log file analysis? First, it needs to be able to handle the different and changing log file structures and formats. It also needs to come up with a knowledge representation schema which is both human and machine readable. Also it is important to have the ability to convert to and from xml for exploiting the power of existing xml tools. Due to the reasons I mentioned earlier, the new framework must be friendly to non-developers and be capable of generating custom reports.

Ok; this is the high level picture of the solution. Mainly it comprises three modules that lie on top of the new knowledge representation schema. The input to the system is a set of log files and the output is a set of reports. The first module, which is the Interpretation module is supposed to provide a “Unified mechanism for extracting information of interest from both text and binary log files with arbitrary structure and format”. In other words it is the part of the framework that helps one to express the structure and format of his log file and point to the information of interest. Output of this module will be the extracted information expressed in the knowledge representation mechanism. The Processing module is the one that keeps the expert knowledgebase to make inferences from this information. As mentioned here it is supposed to provide an “Easy mechanism to build and maintain a rule base for inferences”. What comes out of this module is a set of conclusions drawn on the information. After that it is a matter of presenting these findings to various stakeholders. This is exactly the responsibility of the next module, the “Presentation” module. It should provide “Flexible means for generating custom reports from inferences”.

One important selection here is the way of representing knowledge. This decision must be made carefully because the rest of the solution depends heavily on that. If there is a single factor that determines the success or failure of the entire solution it should be this. After analyzing the drawbacks of existing knowledge representation schemas and the current day’s requirements I decided to use mind map as the knowledge unit in the framework. Mind mapping is a popular activity used by people to quickly organize day-to-day actions, thoughts, plans and even lecture notes. Research proves that mind maps resemble the organization of knowledge in human brain than sequential text does. Therefore it is a good form for human readability. Because of its factual form it is easy to change and visualize contents of a mind map. On the other hand, computers also can process mind maps easily because they can be represented by tree which is a popular data structure that has been there from the beginning of computer programming. All the power of existing tree algorithms can be exploited when processing them. Since xml too can be mapped to a tree, mind maps are easily convertible to and from xml which opens up the door to utilize existing xml tools in processing. In addition, mind maps can be combined with each other in node level which is a desirable feature in mixing data from different sources.

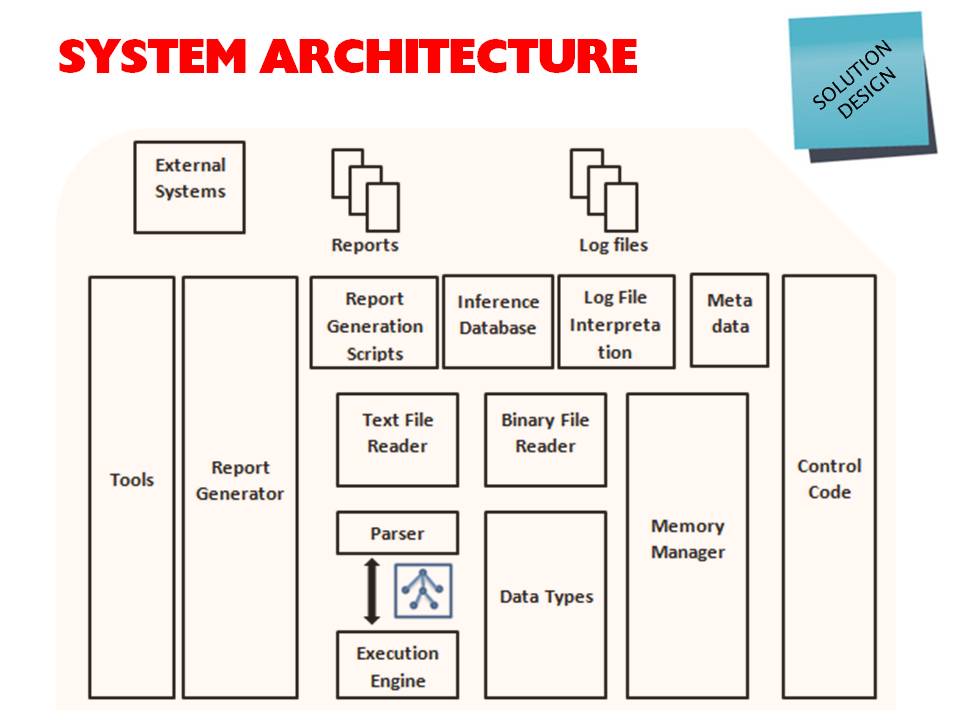
This diagram shows the architecture of the entire system. Parser, Execution Engine, Meta data and the Data types constitute the new scripting language which I will be explaining later. Text and binary file readers serve for the Interpretation module. The system exposes its functionality via a programming interface which is marked here as the Control Code. In addition to the users of the generated reports, External systems also can interact with the system to use the analyzed data.

The framework includes a new scripting language targeting the three main phases in log file analysis. It is centered on mind maps and offers many convenient operations to handle them easily. All the syntax is configurable which means one can define his own syntax to make it look like a totally new language. One main application of this can be localized syntax. Configs for syntax is kept in a separate file in a per script basis. Since mind maps can grow into very big sizes when used for analyzing huge logs it is desirable to have strong filtering capabilities to bring out a set of nodes of interest at a glance. Our new language comes with advanced filtering capabilities for this. Most of them are similar to filtering features in jQuery. One other interesting feature is the statement chaining. With this one can write a long statement like a story in one line and perform operations in many nodes with a single function call. I’ll demonstrate this in the next slide. Then the new language supports built-in and custom data types, functions like all other languages.

The scripting language is specially designed to promote a programming model which I call the “Horizontal Programming Model”. This is inspired by the pattern of referencing in natural language. In a text written in natural language, each sentence can refer something mentioned in the previous sentence, but not something said many sentences before. This neighbor referencing model results in a human friendly flow of ideas much like a story. Horizontal programming is implemented by statement chaining coupled with filtering. A complete idea is expressed in only one or two lines of code. This small snippet is independent of the rest of the script. If we consider the script as the complete rule base then a snippet can be a single inference rule. This is more favored for a non-developer because it is closer to how an idea is expressed in human language. However, the typical general purpose language programming style which I call the “Vertical Programming Model” is also supported in case someone prefers it. This model is different because it promotes distant memory calls and growth of code in vertical direction. In the example provided in the blue box, the variable “Found” is defined in the 1st line and referred only in the 10th line thereafter. This model is better for expressing advanced logic since not everything can be done using the horizontal model.

This diagram briefs the final solution with respect to the solution overview we saw earlier. We have selected mind maps as the knowledge representation schema and the three modules of the solution are going to offer these mentioned features. All the three modules are driven by the new programming language and a set of complementary tools. It’s important to note that the same unified mechanism is capable of serving for significantly different needs that arise inside these three modules.

This diagram illustrates an example use case for the system. Software applications and monitoring tools generate log files and each log file is interpreted through a script. As a result we get a mind map for each log file containing the data extracted from it. Then another script is used to aggregate these data in a meaningful way into a single mind map. We can call this the data map. Now we apply the rule base on this data map to generate inferences. This may result in an inference mind map which can then be used either by external systems for their use or by the presentation script to generate a set of reports to be used by various stakeholders. Though this is not the only way to use the framework, this scenario covers most actions that are involved in a typical log analysis procedure.

With this we can conclude that “The new framework provides a unified platform for generic log analysis. It enables users to perform different tasks in a homogeneous fashion. In addition it formulates infrastructure for a shared rule base”. The possibility of a shared rule base is important because it gives so much power to organizations and communities dealing with same tools and software to reuse expert knowledge.

There are few possible improvements for the framework to make it more useful in the domain. Since some software applications and tools are widely used in software development, the framework can be accompanied with a set of scripts to interpret them so that not everyone has to come up with their own version. One drawback in using the framework’s scripting language for interpreting log files is that the script does not reflect the format and structure of the log file and its mapping to the mind map. Therefore the readability is poor. A solution for this would be developing a new declarative language to map the information of interest in a log file into a mind map and generate the script from the declaration under the hood. I have already done some work on this and have submitted a paper to another conference. Apparently most expert rules are easier put in vague terms than expressing in crisp logic. Therefore it would be a good idea to add the capability to the framework to work with fuzzy rules as well. Although it’s possible in the current implementation to write a script to generate custom reports, the task will be much more intuitive if the report format can be designed in a integrated development environment with a designer. Developing such a designer is one more interesting future improvement.
That ends the presentation and thanks for listening.